Représentation d’un texte en machine
Un caractère ?
Comment enregistrer, de manière optimale, du texte en mémoire ?
De combien de symboles a-t-on besoin ?
- 26 lettres dans l’alphabet, 52 avec les majuscules.
- 10 chiffres
0123456789 - Un peu de ponctuation :
,;:!?./*$-+=()[]{}"'etc. - Quelques caractères techniques (retour à la ligne, espace etc.)
On dépasse mais en se contentant du minimum, on reste en dessous de .
On peut encoder une table assez vaste avec 7 bits.
Idée d’ASCII (1961) : uniformiser les nombreux encodages incompatibles entre eux.
La table ASCII complète
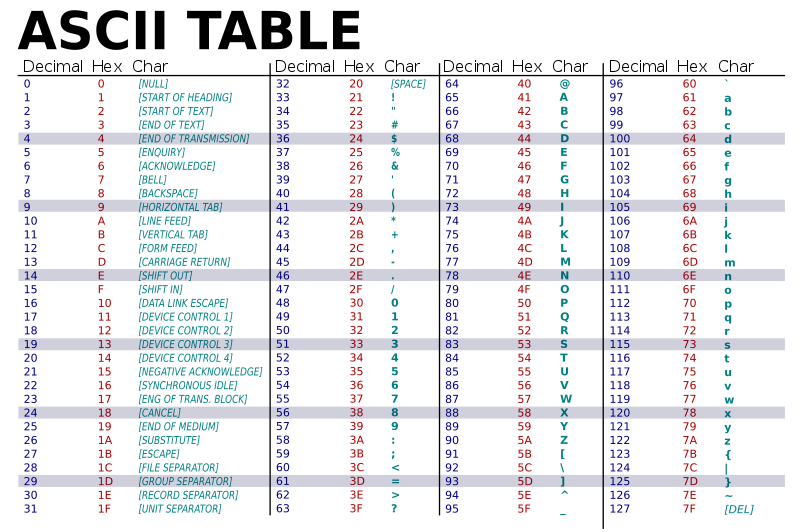
Remarques sur la table précédente
- Tout élément de la table est codé sur 7 bits, 1 octet par caractère suffit ()
- Les chiffres commencent à , les majuscules à et les minuscules à
- Pour obtenir la notation binaire, on part de l’hexa.\newline
Premier chiffre : 3 bits, second chiffre 4 bits
- Seulement 95 caractères imprimables, pas de caractère accentués :
!"#$%&'()*+,-./0123456789:;<=>?
@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_
`abcdefghijklmnopqrstuvwxyz{|}~
Python et la table ascii
Les fonctions chr et ord permettent d’accéder à la table
>>> chr(65) # caractère 65 (décimal)
'A'
>>> ord('A') # numéro décimal du caractère
65
iso-8859-1 ou iso-Latin-1
Comment compléter la table ASCII ?
L’encodage iso-8859-1, dit iso-Latin-1 est apparu en 1986 et correspond à l’Europe de l’ouest.
D’autres versions pour les caractères iso-Latin-2 de l’Europe de l’est etc.
- Reprend la table ascii et ajoute les accents au coût d’un octet supplémentaire.
- Encore incomplet : œ et Œ n’y sont pas !
Ce qui a contribué à leur disparition de nombreux documents écrits dans les années 90… - Windows (Windows-1252) et Mac (MacRoman) ont leurs versions\newline Échange de documents et développement de logiciels plus que pénibles.
Bref, c’est imparfait.
Unicode
L’unicode et en particulier UTF8 vise à résoudre TOUS les problèmes dans UNE norme.
- minimiser l’espace occupé par un caractère
- proposer un encodage adaptable à tous les caractères employés sur terre
- conserver l’ordre de la table ascii de départ
Unicode remonte à 1991, est encore en développement, comporte déjà 137 374 caractères d’une centaine d’écritures dont les idéogrammes, l’alphabet grec etc.
UTF8 est utilisé par 90,5% des sites web en 2017 et dans la majorité des systèmes UNIX (comprenez les serveurs)
Motivation d’unicode : $ et £
Les machines des années 1980 étant fournies avec leur propre encodage, une somme d’argent en dollars se voyait attribuer le symbole monétaire $ aux USA et le symbole £ au royaume uni (symbole monétaire de la livre sterling).
Mais 1\neq$ 1£ et les confusions étaient fréquentes.
On a ensuite, peu à peu, étendu ce projet à tous les symboles existant.
Principe simplifié d’UTF8
- Chaque caractère est codé avec une séquence de 1 à 4 octets.
- Un texte encodé en ASCII est encodé de la même manière en UTF8 (sauf exception)
- Les premiers bits indiquent la taille de la séquence :
0xxxxxxx : 1 octet110xxxxx 10xxxxxxxx : 2 octets1110xxxx 10xxxxxx 10xxxxxx : 3 octets11110xxx 1001xxxx 10xxxxxx 10xxxxxx : 4 octets
- On note
U+XXXXun caractère encodé en UTF8 - La taille est variable (génant pour les développeurs novices), l’espace en mémoire est parfois important
- Un caractère peut avoir plusieurs représentations problèmes de sécurité informatique : certaines opérations interdites sont filtrées en reconnaissant des caractères. Ce problème est globalement résolu.
Python 2 et l’encodage des caractères
Python 2 supporte bien UTF8 à condition de lui demander.
Sans quoi le premier accent va faire planter python 2.
On trouve souvent dans l’entête d’un fichier .py :
#!/usr/bin/env python
# -*- coding: utf-8 -*-
qui signifient :
- Execute ce fichier avec
python, situé dans le dossier/usr/bin/env - l’encodage du fichier est en utf8
Python 3 supporte nativement utf8, on peut se passer de cette précision
Python et l’UTF8
On utilise les fonctions chr et ord
chr(entier)retourne le caractère encodé par cet entier en utf-8ord(caractère)retourne l’encodage utf-8 de ce caractère.
les fonctions chr et ord supportent unicode :)
>>> chr(82)
'R'
>>> ord('R')
82
Martine écrit en UTF-8

WHAT ?
- La lettre é a été encodée en UTF-8 (parce que 2 caractères sont affichés)
En mémoire elle occupe 2 octets (elle n’est pas dans la table ascii) - Ces deux octets ont été décodés en iso-latin1 (1 octet par caractère).