Programmation dynamique⚓︎


1. Retour sur la suite de Fibonacci⚓︎
1.1 Simple et inefficace⚓︎
Comme nous l'avons déjà vu ici, la suite de Fibonacci définie par :
se programme récursivement par :
1 2 3 4 5 6 7 | |
Ce code, d'une grande simplicité, est malheureusement très inefficace.
Exercice 1
Mesurer le temps de calcul de fibo(40).
Correction
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
Le temps de calcul est de plusieurs dizaines de secondes, sur une machine récente. C'est très mauvais !
En cause : la multitude des appels récursifs nous conduit à refaire des calculs déjà effectués.
Observons l'arbre d'appels de fibo(6) :
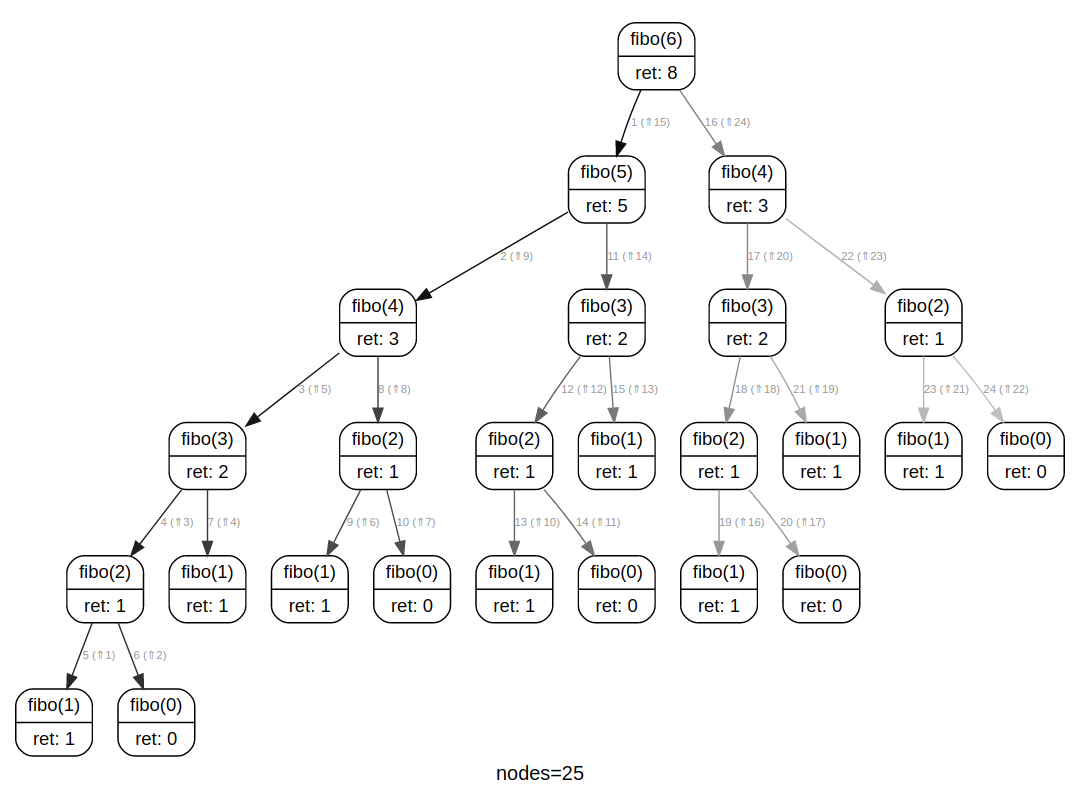
Le calcul de fibo(2) se retrouve ainsi 5 fois dans l'arbre.
Pour résoudre notre problème, nous l'avons divisé en problèmes plus petits, mais malheureusement pas indépendants. Une approche par diviser pour régner est donc impossible.
On dit que les problèmes se recouvrent, ce qui nous amène à refaire des choses déjà faites.
Dans l'algorithme de dichotomie, ou du tri-fusion, les problèmes étaient indépendants et ne se recouvraient pas : on ne refaisait jamais deux fois la même chose. Ce n'est pas le cas ici.
1.2 Se souvenir des belles choses des calculs : la mémoïsation⚓︎
Comment éviter de recalculer (par exemple) 5 fois fibo(2) ? En se souvenant que nous l'avons déjà calculé !
L'idée générale est donc de stocker le résultat de chaque calcul, par exemple dans un dictionnaire. Ainsi, à chaque demande de calcul :
- Soit le calcul a déjà été effectué : on a donc juste à le lire dans le dictionnaire.
- Soit le calcul n'a jamais été effectué : on l'effectue, et on stocke le résultat dans le dictionnaire.
Exercice 2
Compléter le code suivant :
1 2 3 4 5 6 | |
Correction
1 2 3 4 5 6 | |
 Exemple de mémoïsation : Fibonacci
Exemple de mémoïsation : Fibonacci
1 2 3 4 5 6 | |
 le dictionnaire
le dictionnaire dict_fibo doit être à l'extérieur de la fonction, sinon il est réinitialisé à chaque appel récursif !
Exercice 3
Mesurer le temps de calcul de fibo(40) et comparer avec la mesure de l'exercice 1.
Correction
Le temps de calcul est maintenant de l'ordre de
1.3 Quelques remarques⚓︎
1.3.1  Juste une brute-force plus efficace ?⚓︎
Juste une brute-force plus efficace ?⚓︎
Notre technique de mémoïsation ne change pas vraiment la structure du programme : on continue de calculer toutes les valeurs intermédiaires, mais on ne les calcule qu'une seule fois.

1.3.2 Suppression de la variable globale⚓︎
Dans le code précédent, le dictionnaire dict_fibo est à l'extérieur de la fonction. Un dictionnaire étant un type mutable, sa modification à l'intérieur de la fonction ne pose pas de problème. Toutefois, ce genre de pratique est déconseillé : si par exemple on appelle 2 fois la fonction fibo, le dictionnaire n'est pas réinitialisé entre-temps (ce qui dans notre cas n'est pas problématique, mais cela pourrait l'être). Comment éviter cela ?
On peut utiliser une fonction englobante (appelée ici fibonacci ) :
1 2 3 4 5 6 7 8 | |
>>> fibonacci(50)
12586269025
Remarquez la définition d'une fonction à l'intérieur d'une autre. Cela ne pose aucun problème, mais attention, cette fonction n'existe pas à l'extérieur de sa fonction englobante.
1.3.3 Mémoïsation automatique en Python (HP)  ⚓︎
⚓︎
La fonction lru_cache du module functools permet de mémoïser automatiquement une fonction récursive. Il suffit, juste avant d'écrire la fonction, de mettre la ligne @lru_cache (appelée décorateur).
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | |
Essayez en commentant / décommentant la ligne 4... c'est magique !
1.4 De bas en haut⚓︎
La structure récursive naturelle de la suite de Fibonacci nous a conduit vers un programme qui calcule (ou plutôt appelle) les valeurs de haut en bas. (méthode top-down)
Et si on commençait par le bas ?
C'est en fait ce que nous faisons naturellement : si nous devions calculer mentalement le 6ème terme de la suite de Fibonacci, on commencerait par calculer le 3ème, puis le 4ème, puis le 5ème et enfin le 6ème.
Exercice 4
Compléter le code ci-dessous :
1 2 3 4 5 6 7 | |
Correction
1 2 3 4 5 6 7 | |
Cette méthode itérative part du bas pour aller vers le haut. On parle de méthode bottom-up. De manière plus générale, cette méthode est basée sur le fait de résoudre des problèmes de petite taille, puis de plus en plus gros, jusqu'au problème final.
1.5 Bilan des méthodes employées⚓︎
Principes de programmation dynamique
-
Lors d'un calcul effectué de manière récursive, il peut arriver que de multiples appels récursifs soient identiques. Pour éviter de recalculer plusieurs fois la même chose, on peut stocker les résultats intermédiaires. On appelle cette technique la mémoïsation.
Cette technique minimise le nombre d'opérations et accélère grandement l'exécution du programme. Le prix à payer est l'utilisation d'une structure de stockage des valeurs intermédiaires, et donc une augmentation de la mémoire utilisée par le programme. -
Lors d'un calcul effectué de manière itérative, il est parfois plus simple de commencer par une «petite» version du problème pour progressivement remonter vers la solution du problème global.
2. Programmation dynamique et optimisation⚓︎
2.1 Optimisation d'une somme dans une pyramide⚓︎
Problème
Considérons la pyramide ci-dessous :
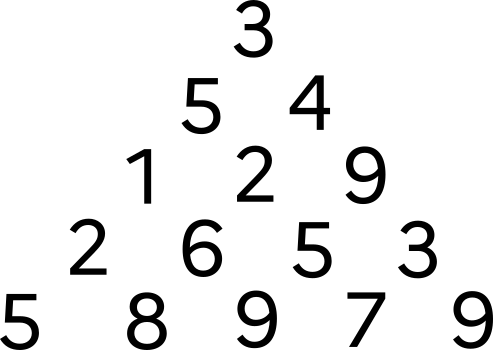
En partant du sommet et en descendant soit à gauche soit à droite, quel chemin donne la somme maximale en arrivant en bas ?

2.2 Problème du plus grand carré blanc⚓︎
Problème
Considérons l'image ci-dessous :

Quel est la taille du plus grand carré entièrement blanc qu'on puisse dessiner à l'intérieur de cette image ?
2.3 Optimisation du rendu de monnaie⚓︎
Problème

Étant donnés une liste de pièces pieces et une somme à rendre somme, peut-on calculer le nombre minimal de pièces pour réaliser cette somme ?
Décidabilité, calculabilité⚓︎

1. Un programme comme paramètre d'un programme⚓︎
Les codes que nous manipulons ressemblent souvent à cela :
def accueil(n):
for k in range(n):
print("bonjour")
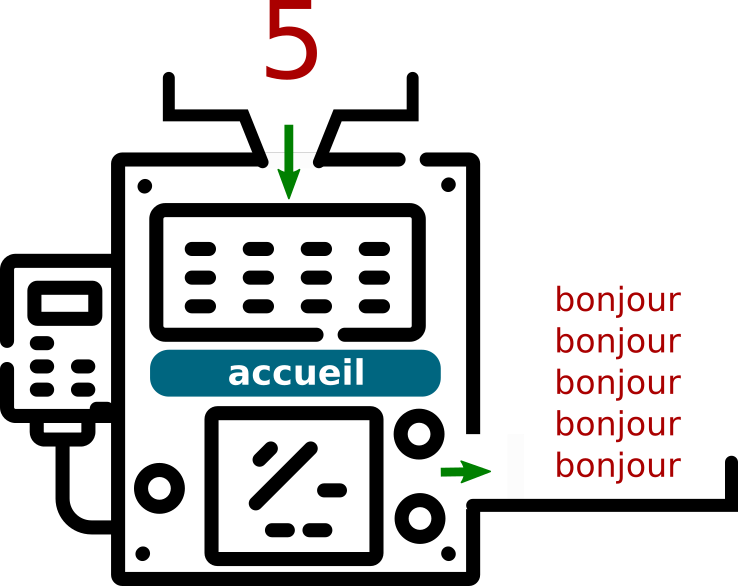
Le programme s'appelle accueil, et pour fonctionner il a besoin d'un paramètre, qui sera ici un nombre entier n.
Voici comment nous pouvons représenter notre machine accueil, son paramètre d'entrée (5) et sa sortie (les 5 «bonjour»)
Maintenant, enregistrons le code suivant dans un fichier test.py :
def accueil(n):
for k in range(n):
print("bonjour")
accueil(5)
Pour exécuter ce code, nous devons taper dans un terminal l'instruction suivante :
python3 test.py, ce qui donnera
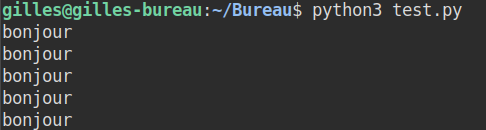
Le programme utilisé est alors python3, qui prend comme paramètre le programme test.py. Ce paramètre test.py est un ensemble de caractères qui contient les instructions que le programme python3 va interpréter.
L'illustration correspondante sera donc :
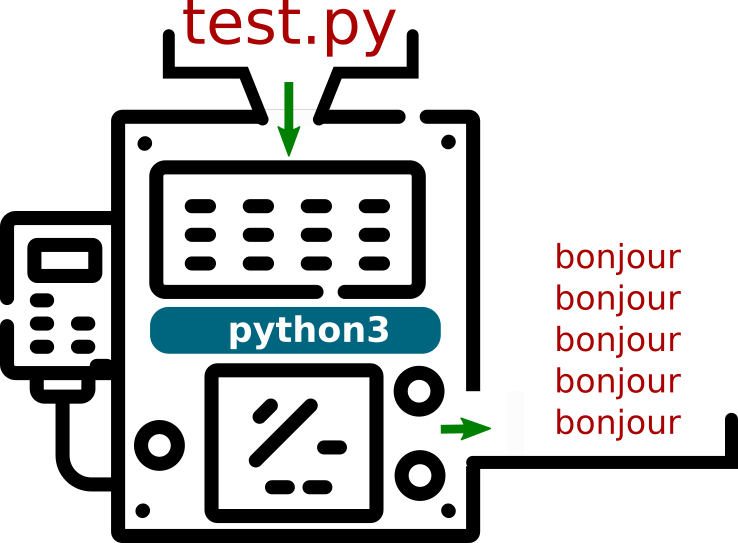
Mais nous pouvons aller encore plus loin : l'instruction python3 test.py est tapée dans mon Terminal Linux, qui lui-même est un programme appelé Terminal.
Et donc :

Conclusion :
Il n'y a donc aucun obstacle à considérer un programme comme une simple donnée, pouvant être reçue en paramètre par un autre programme. (voire par lui-même !)
Les quines
À titre anecdotique, on pourra exécuter en console cette instruction Python :
a='a=%r;print(a%%a)';print(a%a)
2. Mon programme va-t-il s'arrêter ?⚓︎
2.1 Un exemple⚓︎
Considérons le programme suivant :
def countdown(n):
while n != 0:
print(n)
n = n - 1
print("fini")
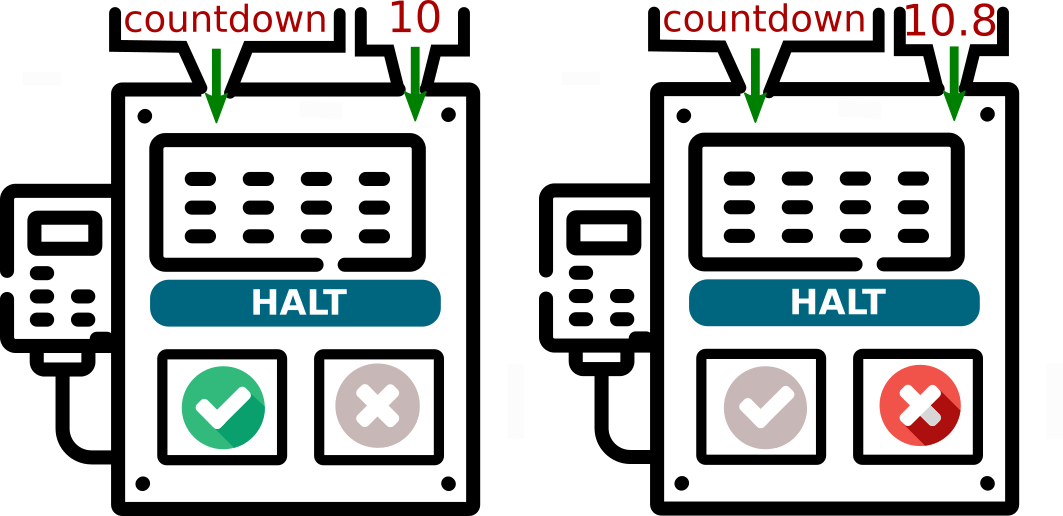
En l'observant attentivement, je peux prévoir que countdown(10) affichera les nombres de 10 à 1 avant d'écrire "fini". Puis le programme s'arrêtera.
Mais que va provoquer countdown(10.8) ?
Comme la variable n ne sera jamais égale à 0, le programme va rentrer dans une boucle infinie, il ne s'arrêtera jamais. Mauvaise nouvelle.
J'ai pu prévoir ceci en regardant attentivement le code de mon programme. J'ai «remarqué» qu'une variable n non entière provoquerait une boucle infinie.
Question : Est-ce qu'un programme d'analyse de programmes aurait pu faire cela à ma place ?
2.2 Une machine pour prédire l'arrêt ou non d'un programme.⚓︎
Après tout, un programme est une suite d'instructions (le code-source), et peut donc être, comme on l'a vu, le paramètre d'entrée d'un autre programme qui l'analyserait.
Un tel programme (appelons-le halt) prendrait en entrées :
- un paramètre
prog(le code-source du programme) - un paramètre
x, qui serait le paramètre d'entrée deprog.
L'instruction halt(prog, x) renverrait True si prog(x) s'arrête, et False si prog(x) ne s'arrête pas.
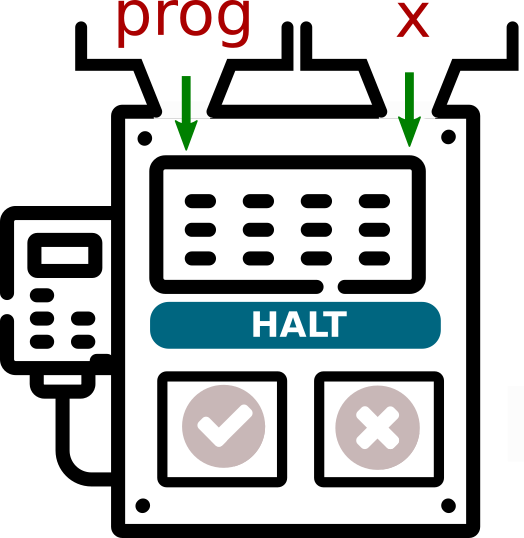
Exemple :
halt(countdown, 10)renverraitTrue.halt(countdown, 10.8)renverraitFalse.
Tentative d'écriture de halt en Python :
def halt(prog, x):
if "prog(x) s'arrête": # mes excuses, je n'ai pas eu le temps de finir totalement ce code
return True
else :
return False
Nous en resterons là pour l'instant dans l'écriture de ce programme. Nous allons nous en servir pour construire d'autres programmes.
2.3 Amusons-nous avec ce programme halt.⚓︎
Considérons le programme :
def sym(prog):
if halt(prog, prog) == True:
while True:
print("vers l'infini et au-delà !")
else:
return 1
On peut remarquer que le programme halt est appelé avec comme paramètres prog, prog, ce qui signifie que prog se prend lui-même en paramètre. On rappelle que ce n'est pas choquant, un code-source étant une donnée comme une autre.
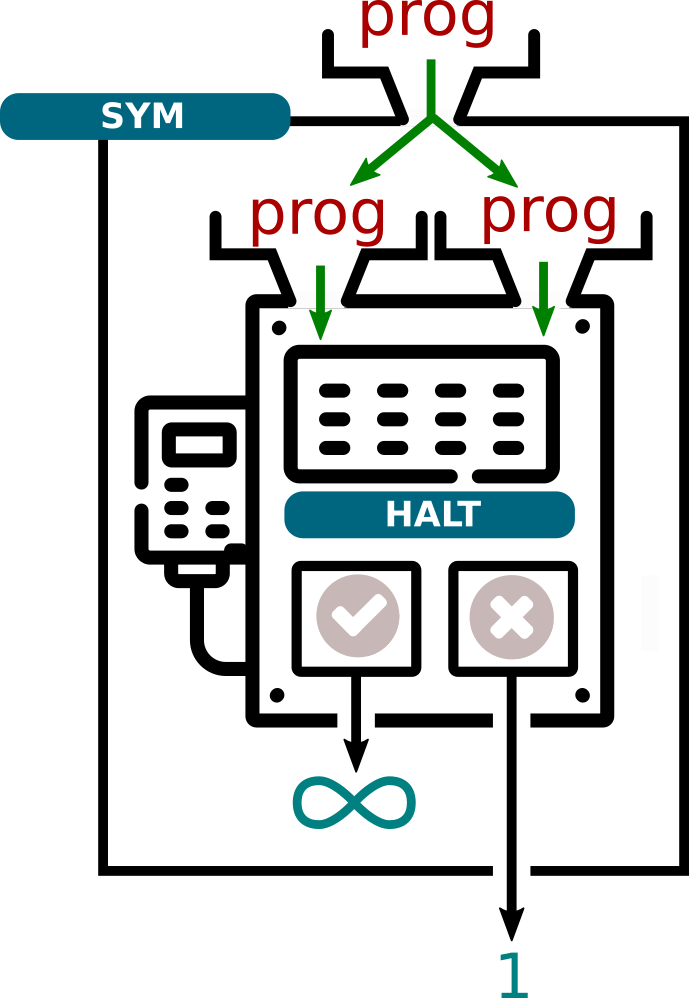
Ce programme sym reçoit donc en paramètre un programme prog, et :
- va rentrer dans une boucle infinie si
prog(prog)s'arrête. - va renvoyer 1 si
prog(prog)ne s'arrête pas.
2.4 Un léger problème ...⚓︎
Puisqu'un programme peut prendre en paramètre son propre code-source, que donnerait l'appel à sym(sym) ?
Deux cas peuvent se présenter, suivant si halt(sym, sym) renvoie True ou False.
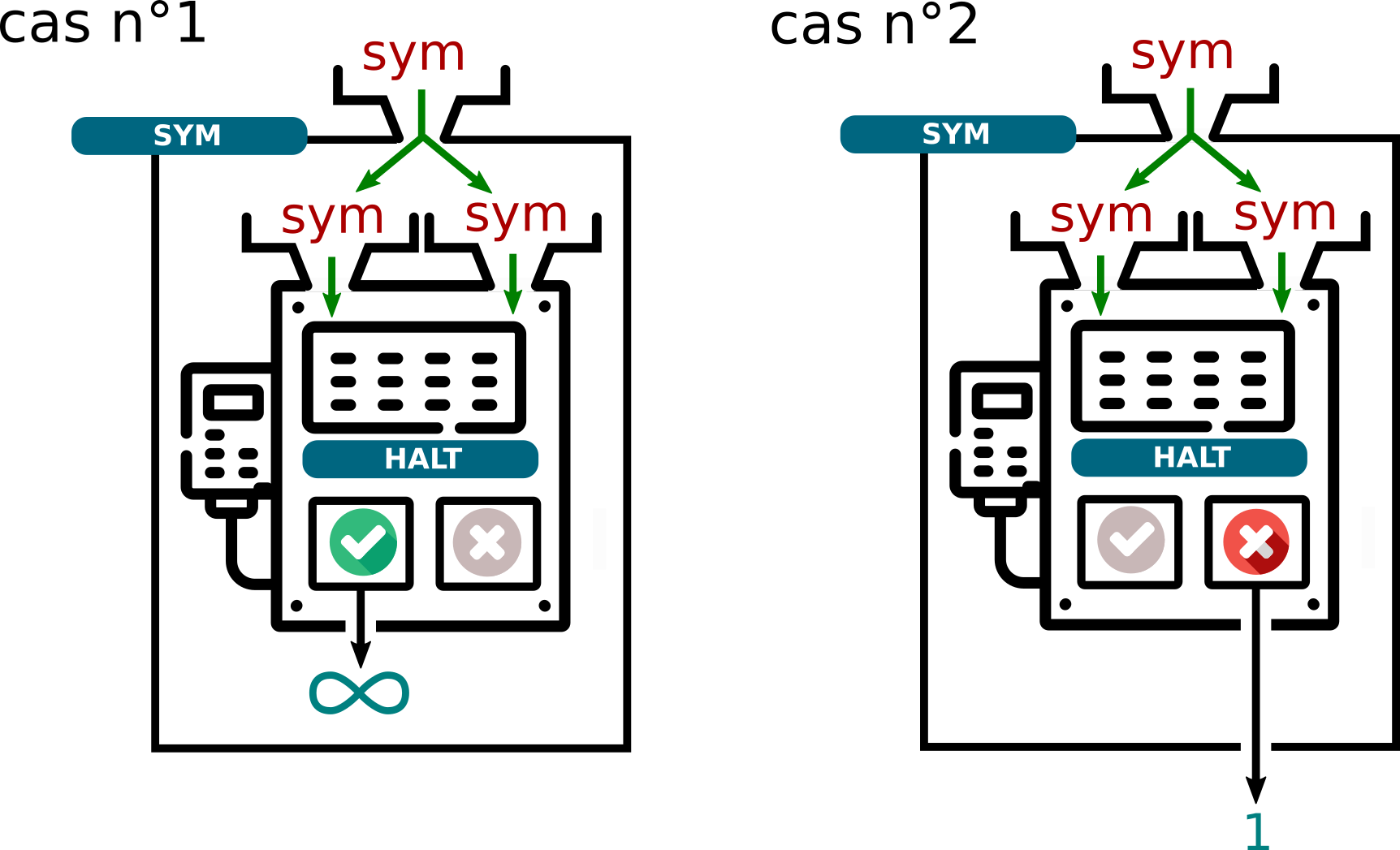
-
cas n°1 :
halt(sym, sym)renvoieTrue, ce qui signifie quesym(sym)devrait s'arrêter. Mais dans ce cas-là, l'exécution desym(sym)rentre dans une boucle infinie. C'est une contradiction. -
cas n°2 :
halt(sym, sym)renvoieFalse, ce qui signifie quesym(sym)rentre dans une boucle infinie. Mais dans ce cas-là, l'exécution desym(sym)se termine correctement et renvoie la valeur 1. C'est une contradiction.
2.5 Conclusion⚓︎
Nous venons de prouver que notre programme halt, censé prédire si un programme prog peut s'arrêter sur une entrée x, NE PEUT PAS EXISTER.
Ce résultat théorique, d'une importance cruciale, s'appelle le problème de l'arrêt.
Problème de l'arrêt 
Il ne peut pas exister de programme universel qui prendrait en entrées :
- un programme P
- une entrée E de ce programme P
et qui déterminerait si ce programme P, lancé avec l'entrée E, va s'arrêter ou non.

Ce résultat a été démontré par Alan Turing en 1936, dans un article intitulé «On computable numbers, with an application to the Entscheidungsproblem».

Pour sa démonstration, il présente un modèle théorique de machine capable d'exécuter des instructions basiques sur un ruban infini, les machines de Turing.
À la même époque, le mathématicien Alonzo Church démontre lui aussi ce théorème de l'arrêt, mais par un moyen totalement différent, en inventant le lambda-calcul.
Tous deux mettent ainsi un terme au rêve du mathématicien allemand David Hilbert, qui avait en 1928 posé la question de l'existence d'un algorithme capable de répondre «oui» ou «non» à n'importe quel énoncé mathématique posé sous forme décisionnelle («un triangle rectangle peut-il être isocèle ?», «existe-t-il un nombre premier pair ?»)
Cette question, appelée «problème de la décision», ou Entscheidungsproblem en allemand, est définitivement tranchée par le problème de l'arrêt : un tel théorème ne peut pas exister, puisque par exemple, aucun algorithme ne peut répondre «oui» ou «non» à la question «ce programme va-t-il s'arrêter ?».
Le théorème de l'arrêt sera étendu plus tard par le théorème de Rice.
Ce résultat démontre que toutes les questions sémantiques (non évidentes) au sujet d'un programme sont indécidables :
- «ce programme va-t-il s'arrêter ?» (le théorème de l'arrêt)
- «ce programme va renvoyer la valeur 12 ?»
- «ce programme va-t-il un jour renvoyer un message d'erreur ?»
- ...
Rice démontre que toutes ces questions peuvent être ramenées (on dit réduites) au théorème de l'arrêt, qui est indécidable.