k plus proches voisins
Nous allons voir aujourd'hui un premier algorithme prédictif qu'on peut classer dans la catégorie des algorithmes permettant de faire de l'intelligence artificielle.
On rappellera donc en introduction que IA veut dire Intelligence Artificielle en français.
En réalité, il s'agit de la traduction de Artificial Intelligence.
Or Intelligence en Anglais ne veut pas vraiment dire intelligence en Français !
Par exemple, Intelligence Service veut dire Service de Renseignements, les services secrets en gros.
Et c'est ainsi qu'il faut comprendre IA : c'est un ensemble de programmes qui ont pour but d'analyser un ensemble de données pour en tirer une conclusion.
Il s'agit donc bien d'un travail d'analyse de données.
Logiciel nécessaire pour l'activité : Python 3 : Spyder, IDLE ou Edupython ...
Prérequis : les activités suivantes
- Python : Notion de distance euclidienne, liste, parcours de listes et surtout les dictionnaires,
- Données :
- Utilisation d'une table de données
- Recherche dans une table de données
A Rendre ✎ : Le TP
1 - Présentation de la méthodes
- En intelligence artificielle, la méthode des k plus proches voisins est une méthode d’apprentissage supervisé.
En abrégé k-NN ou KNN, de l'anglais k-nearest neighbors. - Dans une méthode d'apprentisssage supervisé, on a des exemples que l'on sait classer et qui sont déjà classés.
L'ordinateur apprend avec les exemples et leur réponse, puis teste. - Par exemple pour distinguer si l'on a une photo de chat ou de chien, l'ordinateur va analyser des centaines de photos dont il a la réponse, et apprendre.
- Le terme machine learning vient de l’informaticien américain Arthur Samuel en 1959.
Notre problème est assez simple
- On relève sur des objets de différentes classes (chien ou chat ... ) des paramètres (longueur, largeur, couleur, poids, qualité 1, qualité 2 ..) qui vont permettre de les distinguer.
- On sait donc que pour tel objet de telle classe, on a tels paramètres.
- Par exemple la classe chat (taille, poids, couleur)
- et la classe chien (taille, poids, couleur)
- L'objectif est de pouvoir prévoir à quelle classe appartient un nouvel objet uniquement à l'aide de ses paramètres.
Il s'agit clairement d'un apprentissage supervisé.
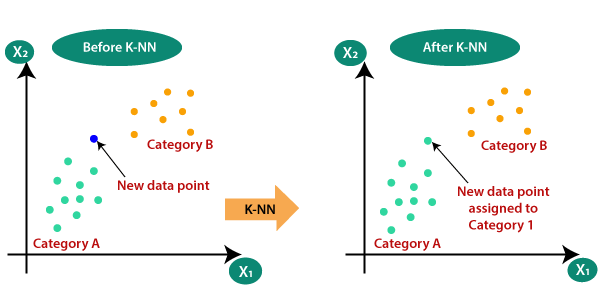
- L'algorithme des k plus proches voisine - Idée générale
- On considère une population dont on connait la classe et les caractéristiques.
- On introduit un nouvel élément dont on ne connait que les caractèristiques et on cherche à lui attribuer une classe.
- Ayant choisi une distance adaptée, on compte les k voisins les plus proches de l'élément à classer.
On verra que le choix de k est crucial. - On lui attribue alors la classe des voisins majoritaires.
Un exemple
Nous allons travailler sur un ensemble de données.
Elles ont été reconstituées à partir des données tirées de la coupe du monde 2018.
Le fichier complet se trouve ici mais nous n'allons utiliser qu'une version tronquée : celle ne contenant que les joueurs des 4 premières équipes, à savoir la France, la Croatie, la Belgique et l'Angleterre.
Nous voudrions voir s'il est possible d'associer un type de joueur (attaquant, milieu de terrain, défenseur ou gardien) en fonction de sa taille et de son poids.
Pour cela, pas besoin de sortir Python dans premier temps : les tableurs comme celui d'OpenOffice peuvent ouvrir le fichier CSV et il ne reste qu'à créer des graphiques.
Voici le résultat :

Bon... Pas de catégorie caractérisée par un type unique de carrure. Mais il y a bien quelques schémas visibles.
Et c'est maintenant que nous allons devoir sortir l'algorithmique : ce n'est pas intuitif mais il existe un moyen de prédire (ici approximativement, on reste sur de l'humain).
Imaginons que vous ayez un joueur à placer. Ici représenté par le point noir (70 kg, 180 cm):

Alors, on lui donne quel rôle à celui là ?
Ici, c'est facile et cela va vous permettre de comprendre le principe de l'algorithme de k plus proches voisins.
Imaginons qu'on parte avec un algorithme des 9 plus proches voisins.
Voici le résultat graphique :

Si on compte, on obtient donc :
- 5 voisins milieux de terrain
- 2 voisins défenseurs
- 2 voisins attaquants
Nous aurions donc tendance à dire que notre joueur a plutôt un profil de milieu de terrain, non ?
Attention : j'ai pris ici un exemple avec une forte influence humaine. Il est clair que la masse et la taille ne permettent pas à coup sur de prévoir le poste d'un joueur. Il s'agit juste ici de prédire à quel poste un joueur sera le plus compétent en ne connaissant que ces deux caractéristiques physiques.
Il y a notamment un problème : deux joueurs avec la même masse et la même taille peuvent être à des postes différents. Il y a en effet des variables cachées (vitesse, accélération, précision ...) J'aurai pu prendre les caractéristiques qu'on trouve dans les jeux vidéos, mais est-ce bien caractéristique ?
Voici donc le principe de l'algorithme des k plus proches voisins : on regarde quelles sont les catégories des k enregistrements les plus proches de celui qu'on étudie et on pourra répondre. L'algorithme répond en fournissant la catégorie (ou les catégories en cas d'égalité) la plus représentée.
Attention néanmoins à la qualité de vos données : c'est là l'une des plus grandes difficultés des techniques d'intelligence artificielle : ne pas biaiser le résultat en fournissant des données incorrectes !
La première critique qu'on peut avoir sur notre jeu de données (les joueurs des 4 premières équipes) est qu'il n'y a pas le même nombre de joueurs dans chaque catégorie alors que les catégories ne sont pas clairement marquées par une zone. Du coup, celle qui apparaît le plus souvent à statistiquement un avantage certain.
Nous allons donc remédier à cela en rajoutant des joueurs dans les catégories les moins fournies.
Notre collection de base contient :
- 23 attaquants
- 33 défenseurs
- 12 gardiens
- 24 milieux de terrain
Il faudra donc monter à au moins une trentaine de joueurs par catégorie.
Du coup, j'ai récupéré également certains attaquants, gardiens de but et milieu de terrain dans les équipes suivantes dans le classement.
Ensuite, j'ai créé deux jeux de données de façon aléatoire :
- 75% des joueurs par catégorie pour créer le jeu d'apprentissage ou d’entraînement.
- Les 25% restants vont servir à créer le jeu de tests : nous allons tenter de comparer le poste réel des joueurs de ce jeu avec le poste que l'algorithme donne.
Voici les rendus graphiques de la nouvelle collection d'entraînement :




Le but est d'avoir une collection de données fiables qui donne à chaque enregistrement un descripteur ou attribut précis.
Notre collection est initialement stockée dans un fichier CSV.
A titre d'exemples, voici les trois premières lignes du fichier CSV :
Poste,Taille (cm),Masse (kg)
Attaquant,178,80
Attaquant,184,78Une vidédo expliquant le problème
2 - Etude d'un exemple
Description : Le jeu de données sur les Pokémons
Nous allons ici appliquer l'algorithme des k plus proches voisins sur un exemple concret.
Ce jeu de données Pokémons est un jeu de données multivariées.
Le jeu de données comprend un échantillon de 34 Pokémons : leur type (Psy ou Eau).

Deux caractéristiques ont été mesurées à partir de chaque pokémon : leur points de vie et la valeur de leurs attaques.
- Voici le TD : TD - K plus proches voisins.
Activité publiée le 25 05 2020
Dernière modification : 16 05 2021
Auteur : Andjekel
Source : ows. h